

Advantages of a Twitter API database cache
The purpose of a Twitter API database cache is simple. You need to decouple your Twitter application from the Twitter API. The foundation of this approach is to separate the process of gathering new tweets from the presentation layer that displays the appropriate data on your website as quickly as possible.
This architecture will create a wall between the Twitter API and your user interface. On one side is the API and your code that collects data from it. On the other side is the code that delivers results as a well behaved Web application to your users. In the middle are the database design and programming techniques needed to store the tweet data in a normalized database schema that has been optimized for the queries your Twitter apps need.
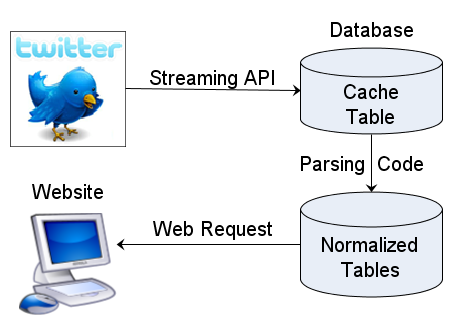
There are many advantages to this architecture:
- Rate limit compliance. Any use of the Twitter API has to have rate limit compliance built into the architecture. It is impossible to predict what the rate limits will be at any time, since they are subject to frequent changes to allow Twitter to adjust to demands, such as during the 2010 World Cup. One thing is certain, you can’t have your website functionality tied directly to the API, because when the API reaches its rate limits your site will start failing. The best way to limit your use of the API is to have a central set of code making a minimum number of calls, and then storing the results in the database cache. That allows your website to deliver any number of pages with no chance of failure.
- Performance optimization. To put it politely, the Twitter API’s performance varies over time. By limiting your website app to only calling your database server, you are in complete control over performance. If your site traffic increases, you can make the decision to add more horsepower on the server side. If the API starts slowing down, you may have a lag in the delivery of tweets, but your pages will still load quickly, which is what users notice most.
- Twitter fault tolerance. One of the greatest benefits of decoupling your website app from the Twitter API is the ability to keep functioning when Twitter is down. By always calling your own database, you can be certain that a failure on Twitter won’t stop your app from displaying valid pages. If your site only aggregates tweets for display, the worst that will happen is that you will have to continue showing old tweets. If you also perform other API functions, you will have to display your own error messages for the user, but this is still under your control, and you can choose to queue user requests for later processing.
- Protection from Twitter API changes. The API is “evolving” at a fairly rapid rate, and backwards compatibility is not always maintained, so you need to plan for failure of your API calls. The most famous example was the transition from basic to OAuth authentication. Especially during these transition periods, when bugs in new API code are being resolved, it is nice to know that your website app will continue to have a stable interface. Decoupling the website app from the Twitter API means that API changes only require a change to the API calls. Your own website requests to your database will most likely be able to remain the same. Even if you do decide to change your database functionality, you can schedule these changes according to your own development plan.
- Multiplexed tweet delivery. Twitter acts as if there is a one-to-one correspondence between each “app” and the Twitter API calls made. This may be true, but as your use of the API grows you will find that you might have multiple apps or websites all sharing the same set of Tweet data or account management calls to the API. By having a central access point to the Twitter API you can choose to build any number of websites that all share the same database. This lets you aggregate information about user accounts as well as tweets in a central database, resulting in much lower rates of API usage. It also gives you some independence from Twitter, since your apps are not as vulnerable to direct suspension of API use.
- Long-term tweet archive. The Twitter search tools are extremely limited in the age of tweets that are available. At times this has ranged from seven days to as short as 24 hours. There are often requests on the Twitter developers mailing list for methods of accessing older tweets, and the answer generally comes down to start collecting tweets in advance. If you start saving all the tweets you gather from the API in a local database, you will soon accumulate a valuable dataset that your clients will be able to use in new and valuable ways over time.
- Tweet data mining. Once you have a long-term archive of tweets, the real fun begins. Datamining for patterns of word usage and user behaviors allows you to create a wide range of functionality. One area that I’ve found very useful for clients is ranking users on various criteria for following purposes or as sales leads. You never know how people really interact on Twitter until you can gather the stats from real-world data. One example I remember is a client who claimed that lawyers would never use Twitter in a way that I described. I was able to deliver a detailed analysis of thousands of users who identified themselves as lawyers in their profile and who did indeed do these types of things on Twitters. This led to some very interesting lead generation tools.





