Free Source Code – Twitter Database Server: Code Architecture
Twitter Database Server
Download
Install
Code Architecture
MySQL Database Schema
Phirehose Library
140dev_config.php
db_config.php
db_lib.php
db_test.php
get_tweets.php
monitor_tweets.php
parse_tweets.php
Twitter Display
streaming_framework
This core Twitter database server module collects tweets from the Twitter streaming API and distributes the data to a series of MySQL tables that support the rest of the code in the 140dev Twitter framework.
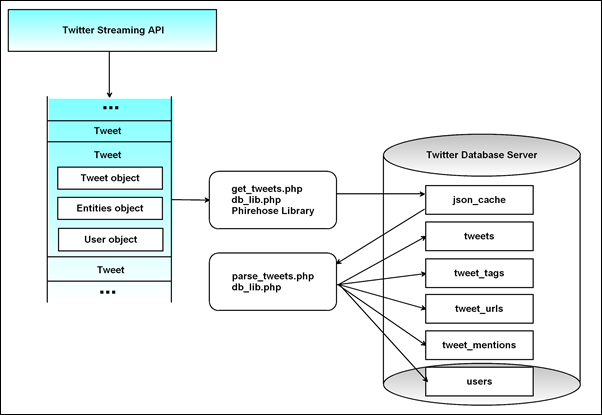
The database is populated in two steps: getting the tweets, and parsing them into multiple tables. It is important to separate these operations, because tweets may be sent by the Twitter API at a very fast rate. If each tweet is parsed and inserted into multiple tables as it is received, the code and database may not be able to keep up with the data flow, and tweets will be lost. My solution is to store the tweets as they are received in a simple cache table without doing any parsing. A separate process does the parsing and storage into separate tables.
The first step of collecting tweets is done by get_tweets.php, which is run as a continuous background process. When a new tweet is received the Twitter streaming API, get_tweets.php uses db_lib.php to insert it into the json_cache table. The connection with the Twitter streaming API is maintained by the Phirehose library.
The Twitter streaming API returns data in JSON format. To make the collection process as fast as possible, the entire JSON payload for a single tweet is saved to the database as a single string without any parsing.
A separate background process is run for parse_tweets.php, which gets the JSON data for each tweet from the json_cache table, parses it into it’s component parts, and inserts them into separate table for use by the other modules in the 140dev framework. Once again, db_lib.php is used to manage the MySQL code.
The rest of the 140dev modules are able to rely on this database of tweets and supporting data without having any direct contact with the Twitter API. Once you install the Twitter database server code, you can build your own Twitter apps that are assured of a real-time source of Twitter data.